Multilingual Document Processing
Native Asian document processing, not a language pack
Western document processors are Latin-script engines with Asian language support retrofitted. Staple was trained on Asian documents from the start. 300+ languages, single deployment, no templates.
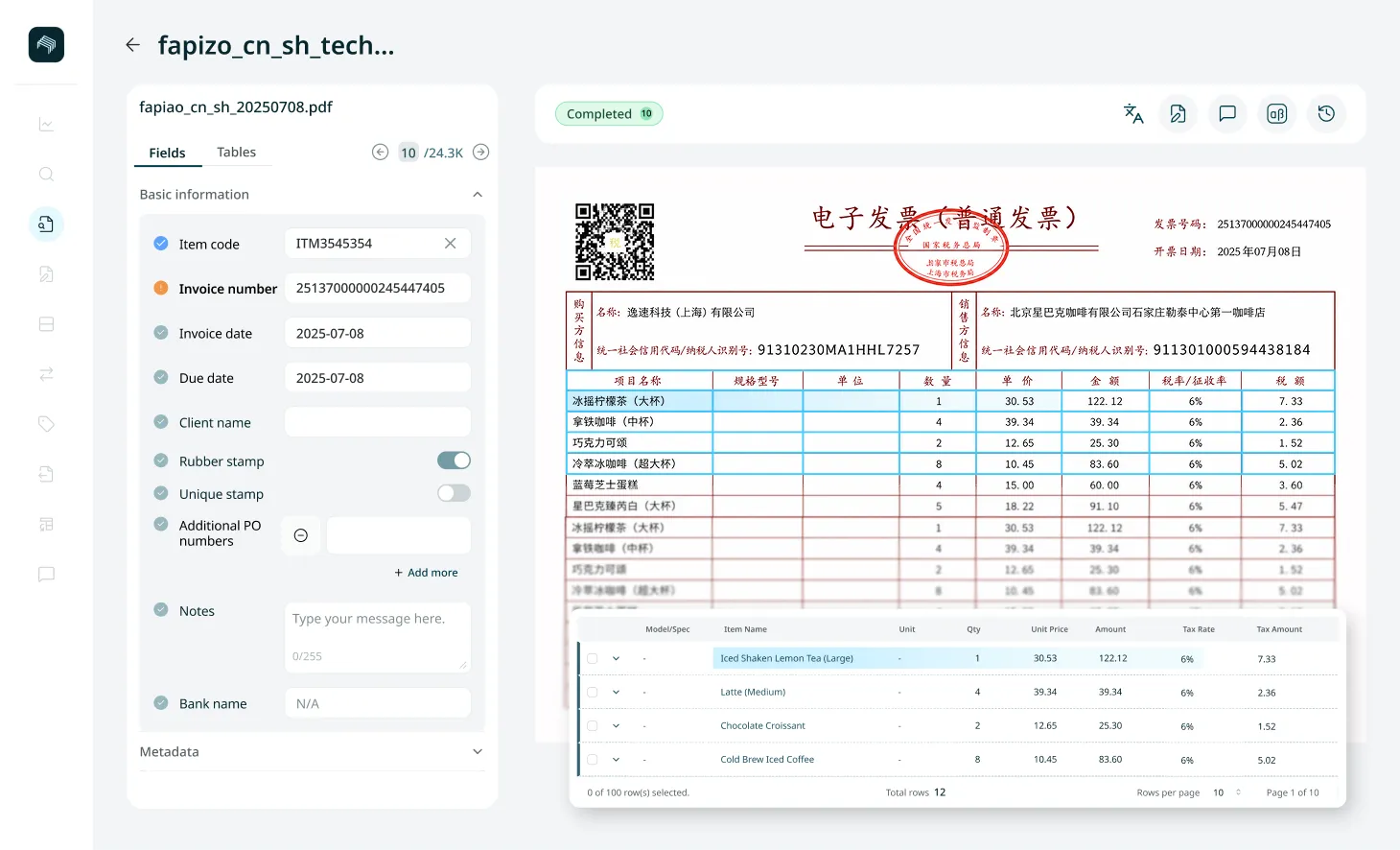
Why most document processors fail on Asian documents
The failure is structural. Western document processors have Latin-script engines with a translation layer on top of OCR tools that were never trained on Asian language characters
Production systems, not pilots at enterprises that evaluated the market and chose Staple.
Mixed-language documents cause errors
Supplier name in Chinese, line items in English, tax ID in Thai: a Latin-script engine processes in one language mode and drops the rest

Rubber stamps aren't recognised
Text layered over a background at an angle. Most Western tools can’t isolate stamp text from the document

Handwriting fails
Latin handwriting recognition does not transfer to Thai, Vietnamese, or Chinese handwriting. Character shapes and stroke patterns are different
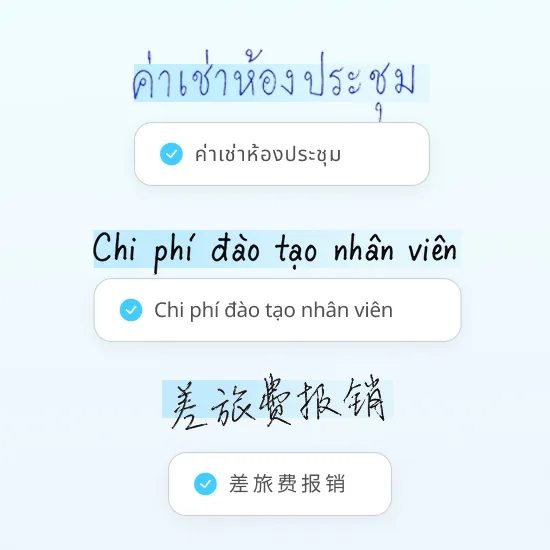
How Staple processes 300+ languages

Native Asian language character support
Bahasa Indonesia, Bahasa Malaysia, Korean, Simplified and Traditional Chinese, Thai and Vietnamese. Models are trained for each script, not translation layers. 300+ languages total for global supply chains.

Handwriting recognition trained on Asian scripts
Thai handwritten annotations, Chinese corrections, and Vietnamese notes processed in the same pipeline as printed text.

Rubber stamp extraction
Stamp impressions separated from the document background and extracted as structured fields. Relevant for APAC invoices and delivery documents where stamps carry legal significance.

Mixed-language documents in a single pass
A document with a Chinese header, English line items, and a Thai tax number is processed as one document. No routing or setup per language.

Template-free
No templates, no rules, no per-language setup. Add a new supplier from a new market and Staple processes their documents without reconfiguration.
What language packs get wrong
Language packs break on real documents
Most document processors are Latin-script engines with an Asian language pack bolted on. The pack works on printed, standard-format documents. It breaks on handwriting, rubber stamps, non-standard layouts, and mixed-language documents. The actual documents in a global supply chain.

The difference with Staple
Handwritten delivery notes with a rubber stamp and a bilingual header are processed in one pass, not routed to a bilingual team member. The difference shows up in the number of documents needing bilingual human review.
A single document with Chinese, English, and Thai fields processed in one pass
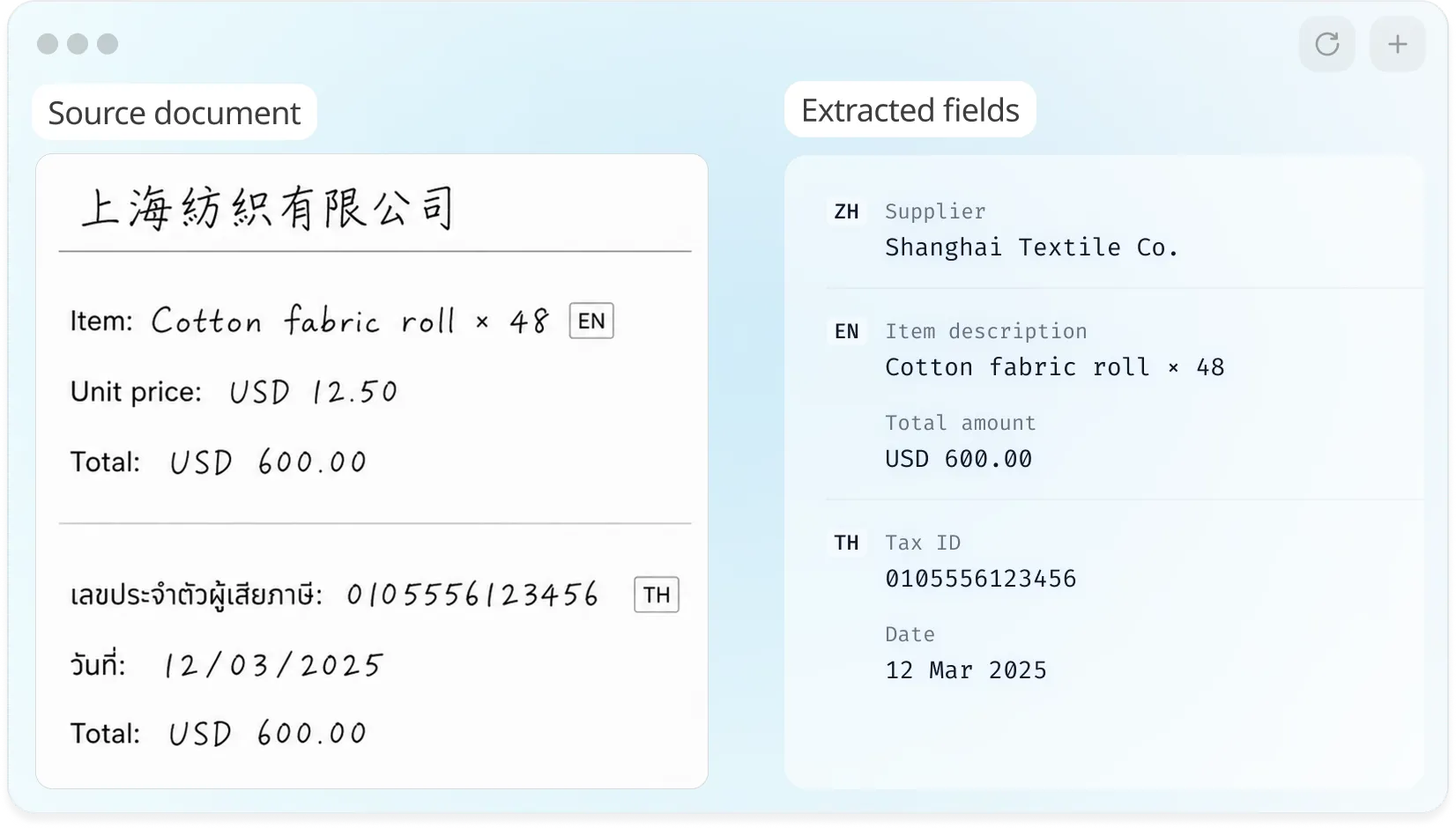
Global FMCG
99.6%
Accuracy across Chinese, Korean, Thai, and Vietnamese, including handwriting and rubber stamps, in a single deployment. No per-language configuration, no bilingual exception team
“Our company is using another OCR tool that struggles to recognise dot-matrix documents, however, it worked perfectly with Staple at almost 100% accuracy.”
Regional IT Manager
Global FMCG Brand
Across Staple’s enterprise customer base, multilingual extraction runs at 95–99.6% accuracy depending on document type and language mix.




See Staple process your multilingual documents
Book a 30-minute demo. Bring your Thai receipts, Chinese purchase orders, or Vietnamese delivery notes. We will run extractions on your files.