
Quick answer:
If you ever wanted to organize your digital photo closet or find pictures of yourself or your friends in a heap of Gbs of data, you have come to the right place. In this blog, you will learn about how you can detect and filter pictures of your friends from an album of thousands using face recognition with deep learning. After a brief overview of the basics of face recognition, we will build an album organizer for your custom dataset. All you need is about 5–10 pictures in advance for the model to recognize your favorite people (including yourself).
Our brain is great at memorizing the faces of the people we meet or interact with a bunch of times. A computer needs to identify unique features of a face such as height/width of the face, nose, lips, average color, the relative distance, and angles between them. We call this information a “feature vector” or a “face encoding” which is basically quantification of a face in terms of its visual appearance encoded in some (128 here) real numbers which a computer can process (see Image 3) and understand.
Here we use theface recognition library to create a 128-dimensional (128-D) feature vector for the face of interest. You can find more details about this library and how it works in this article and pip install it with pip3 install face-recognition.This library creates feature vectors using the OpenFace project (face recognition implementation in Python and Torch) based on the FaceNet model, given by Schroff and co-authors in 2015. The FaceNet is a deep convolutional neural network that uses a set of three images for each training instance: anchor (reference face), positive (same face as anchor face), and negative (different face as anchor face). The deep learning metric for this training process is also known as the Triplet-loss function which minimizes the distance between an anchor and a positive, both of which have the same identity, and maximizes the distance between the anchor and a negative of a different identity.
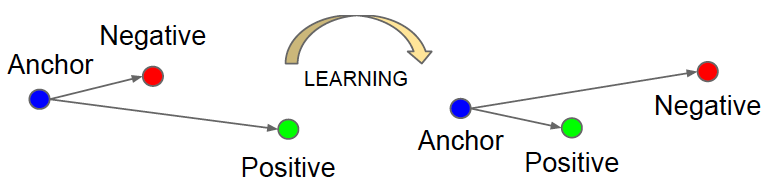
The network is trained such that the 128-D feature vector of every face (even in different images) of the same person is close to each other and at the same time is far away from the 128-D feature vector of any face of some other person. In this context, the notion of “closeness” of feature vectors is quantified by L2 distance and in turn, provides a way to characterize similar-looking faces. Image 1 shows a representation of the learning processes where the triplet-loss minimizes the L2 distance between the feature vectors of anchor and positive while maximizing the distance between the ones of anchor and negatives.
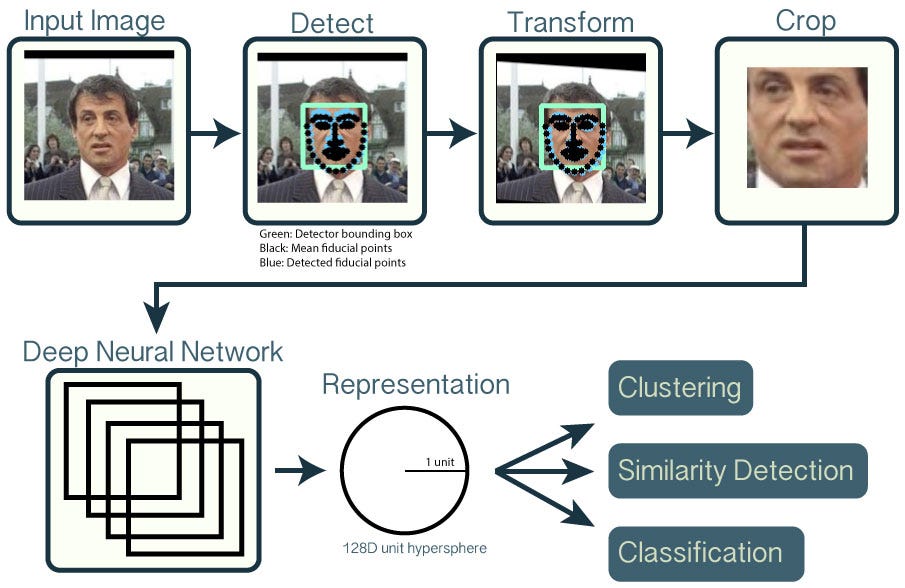
Behind the scene, the first step is to detect all the faces in the input image using the Histogram of Oriented Gradients or some deep learning method. This is followed by the finding face landmarks to perform image transformations for compensating bad illumination and side-pose of the face. The cropped image is then fed to a trained deep neural network (FaceNet) that generates a 128-D feature vector that can be further used for classification, similarity detection to other faces, or general clustering. The pipeline in Image 2 shows the steps involved in face recognition.
Remember we are not training any deep neural network in this blog to create the feature vector but merely accessing a pre-trained one using the face-recognition library. This is mostly because training such neural nets requires a dataset of ~3 million images and consumes enormous computational resources. You can also refer to this article about face recognition with deep learning by Adam Geitgey if you want to learn about face recognition in detail.
For building an album organizer, there are 2 keys steps:

Suppose you have six friends: Chandler, Joey, Rachel, Monica, Phoebe, and Ross and you want to sort out their pictures from thousands of images. As an input, we need a few pictures of your friends so face recognition can construct their individual feature vectors. We can organize them in a directory structure like this below.

FriendsData has sub-folders, each with about 5 pictures of your friends.album.py contains the code for converting your friends’ pictures into their respective face encodings (that would be stored in friends_face_encodings.pickle ).recognize.py finds the encodings of faces in the target picture, and compares them to your friends’ encodings and determines if they match. If there is a match, it draws a bounding box around your friends’ faces in the target picture and labels them.TestData and OutputData are directories for storing the pictures of the album you want to sort and the output pictures with your friends’ faces labeled on them after running recognize.py script.The first step (see code below) involves collecting the paths of all your input images of your friends (in the folderFriendsData) in a listdatapaths (line 56). In the function get_encodings , we loop over all the image paths, get the name of the friend in that image (line 22), identify the bounding box around the face (line 29), and construct their corresponding face encodings (line 32). We store their name and the encoding in a dictionary data and dump it in a pickle file friends_face_encodings.pickle (line 44).
----------
----------
In the first step, we made a database of feature vectors of all our friends’ faces and saved it as a pickle file. Now we have the identities of our friend’s face in terms of their feature vectors.
In the second step (see code below), we first load the unknown test images (line 36) from the directory from which we need to recognize the familiar faces of our friends. In each test image, we detect the bounding boxes of the identified faces (line 39) and make face encodings for each of them (line 40). Once we have all the encodings of the faces in the test image, we compare each of them with our reference feature vectors in the database. If we get even a single match, we get the name of the face which had the highest number of votes. For example, we have 30 face encodings here in the database saved in friends_face_encodings.pickle and we detected 1 face in the test image. We compare this 1 face with all 30 encodings using thecompare_faces function (line 47). This function computes the Euclidean distance between our test image and all the other 30 images in the database. If the distance is below a certain threshold, it returns True but otherwise False. Therefore, we get a list matches of length 30 with boolean values such as [True, True, True,…, False] each indicating whether the test image matched the reference face encoding or not. We then extract the indices matchedIdxs where we hit a match and get the respective name from the loaded pickled file (that we saved from the script album.py) and get the vote count counts. The name with the maximum votes wins. If no match was found, we just label the face as Unknown.
We save the output image in the output_dir with labeled faces and return a filemap dictionary with keys as the names of your friends and the values as a list of filenames they were detected in. This dictionary can be further used to sort out the pictures. Here are a few examples of the test images and the detected faces in them:
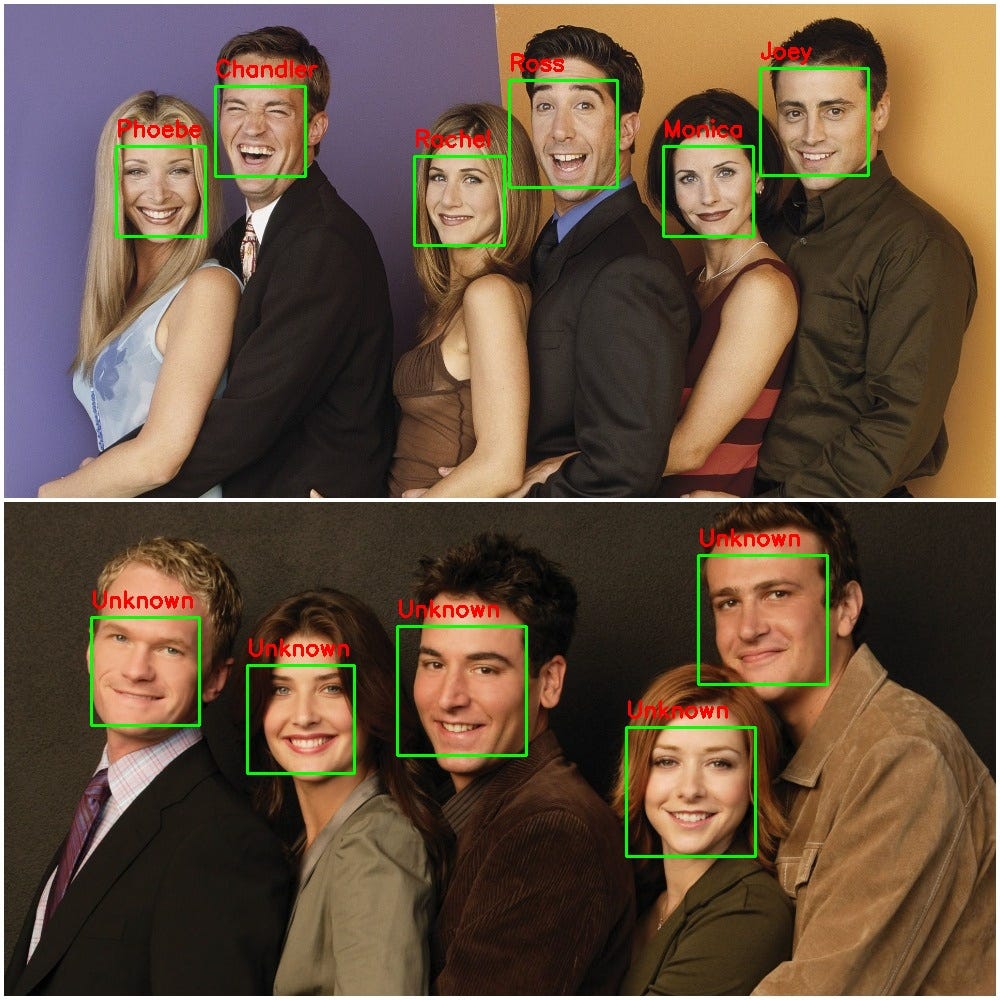
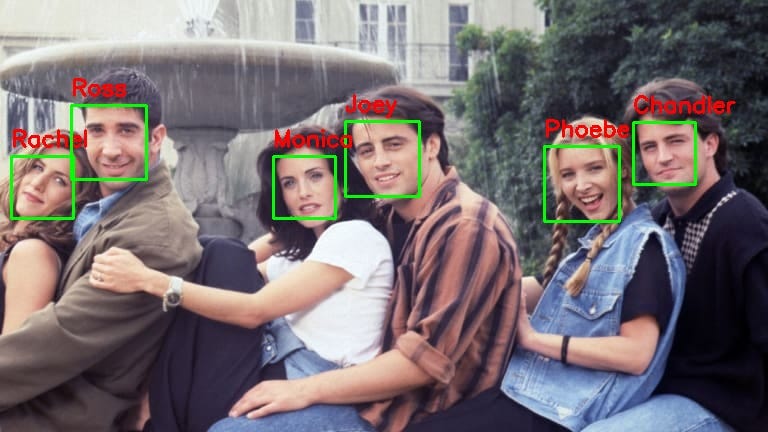
It’s needless to say, the more encodings we have in our reference database, the more accurate our detection would be. Have fun with it! Re-organize your album, find out which celebrities you look like, or just filter out your pictures from a random mess of pictures. Here is a link to the full code on Github. Feel free to leave any comments or suggestions related to this blog.
References
