
Quick answer:
A pragmatic guide to training a Mask-RCNN model on your custom dataset
In the field of computer vision, image segmentation refers to classifying the object category and extracting the pixel-by-pixel mask of the objects from an image. So in addition to object classification and object localization, we also obtain information about which exact pixels are part of the object of interest in the image.
Mask-RCNN is a deep-neural network (an extension of Faster-RCNN) that carries out instance segmentation and was released in 2017 by Facebook. This blog post aims to provide brief and pragmatic guidance on the Tensorflow implementation of Mask-RCNN. So if you are not familiar with CNNs or Mask-RCNN, I recommend going through this blog or reading the original paper by Facebook AI Research before proceeding further.
In general, Mask R-CNN has two stages after a CNN feature extractor extracts image features:
At the end of this blog, you will be able to do the following tasks:
For the ease of labeling objects, I chose the task of recognizing and extracting masks of footballs in the images. The first step involves collecting your dataset if you don’t already have one for your application. Feel free to skip this step if you already have your own dataset.
For scraping images, we need a tool that can simulate a human user who manually downloads images from Google. Selenium is an open-source web-based automation tool that can get the job done by connecting Python with your web browser (we will use Google Chrome here). You also need a web driver for your corresponding Google Chrome version (find out your version by clicking ‘About Google Chrome’). You can download the driver here. For example, I had Version 85.0.4183.121 so I downloaded Chrome version 85.
pip3 install seleniumchromedriver. Place it in the same directory as the python script scrape_images.py below.
In the script below, selenium launches a dummy Chrome browser which searches google for the query words (given by the queries in the code below), fetches the URLs of the images from google, downloads, and saves them to your local folder scraped_images. For each query, it can download about 100 images given by the parameter NUM_IMAGES. Run the script using the python3 scrape_images.py in the terminal and it will save the downloaded images in the folder scraped_images. Remember to change your query words and the number of images you want to download for each query. You might get an error for some of the images as some images might be just inaccessible and some might give you errors while downloading but you can just add more query words if you want more images. You can filter the appropriate images according to the application that you are building. Here is a snippet from the code but you can download the full script here.
---------------
---------------
Although there are a number of labeling tools available, I used VIA as it is very intuitive, light-weight, and easy to use. You can just open it in your browser with this link, upload your dataset and begin labeling. You can choose different region shapes for labeling such as circle, oval, rectangle, or polygon. Since my object of interest was football, I chose a circle for a few and polygons for others. You should set the region_attributes (for example class_name, class_id, image_quality, etc) in the beginning before you start labeling. Learn a few keyboard shortcuts to speed up the training process. I prepared two batches for labeling, one for training, and one for validation. You can preview the annotations using Annotations → Preview Annotations and export them as a JSON file.
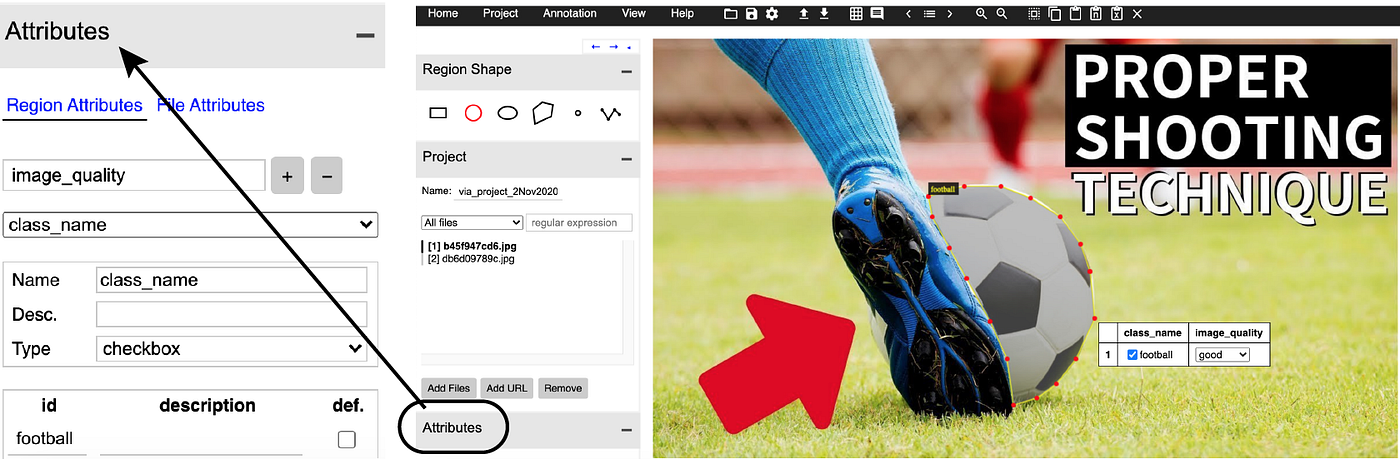
At the end of the labeling process, my folder structure had two folders train and val with their respective images and annotations in files annot.json

Now that we have our dataset and the labels ready, we are ready to set up our Mask-RCNN project. A well-known implementation of Mask-RCNN can be found here by Matterport. Although it is only compatible with Tensorflow 1.3 and Keras 2.1.0, a lot of people have come with a version that is adapted to work with Tensorflow 2.0 which has its newly incorporated Keras. I used a version by TomGross and you can access it by cloning the git repo below.

This will make a folder named Mask_RCNN which will have your files and sample scripts. You can copy the folder named mrcnn and coco weights file mask_rcnn_coco.h5 inside Mask_RCNN folder and placed them along with football_data folder so the directory structure looked like this where football_segmentation.ipynb is the jupyter notebook that we will use for training and logs is a folder that we make to hold the trained model checkpoints and tensorboard information.

With the directory structure already set up in Step 3, we are ready to train the Mask-RCNN model on the football dataset. In football_segmentation.ipynb below, import the necessary packages and modules from mrcnn folder, define the root directory, coco weight path, and logs directory. The modules model and utils from mrcnn have functions and classes for constructing the Mask-RCNN architecture.
-----------------
-----------------
The implementation by Matterport already has a base configuration that we import in the code above on line 5. However, for our custom dataset, we need to add a new class and overwrite the configuration in the parent class that it inherits. To see the values of the hyperparameters in the base configuration (for example, LEARNING_RATE, STEPS_PER_EPOCH, etc), refer to the parent class in the script Config.py. The custom configuration is defined in the FootballConfig class in the code below.
-----------------
-----------------
You can visualize the mask and the corresponding image using the code below. Remember to replace the mask pixel value of 1 with 255 in lines 90 and 93 above. The image and the corresponding mask are shown below.
-----------------
-----------------

For training, we need to load the configuration and functions defined above in FootballDataset class, load, and prepare the dataset for training and validation using prepare function. The model is imported as modellib and the configuration defined by FootballConfig is used to initialize it. We train the last layers of the model with coco weights (line 16) for 30 epochs and the default learning rate. You can tune these hyperparameters. There are default callbacks for TensorBoard and saving of checkpoints for each epoch in the logs folder.
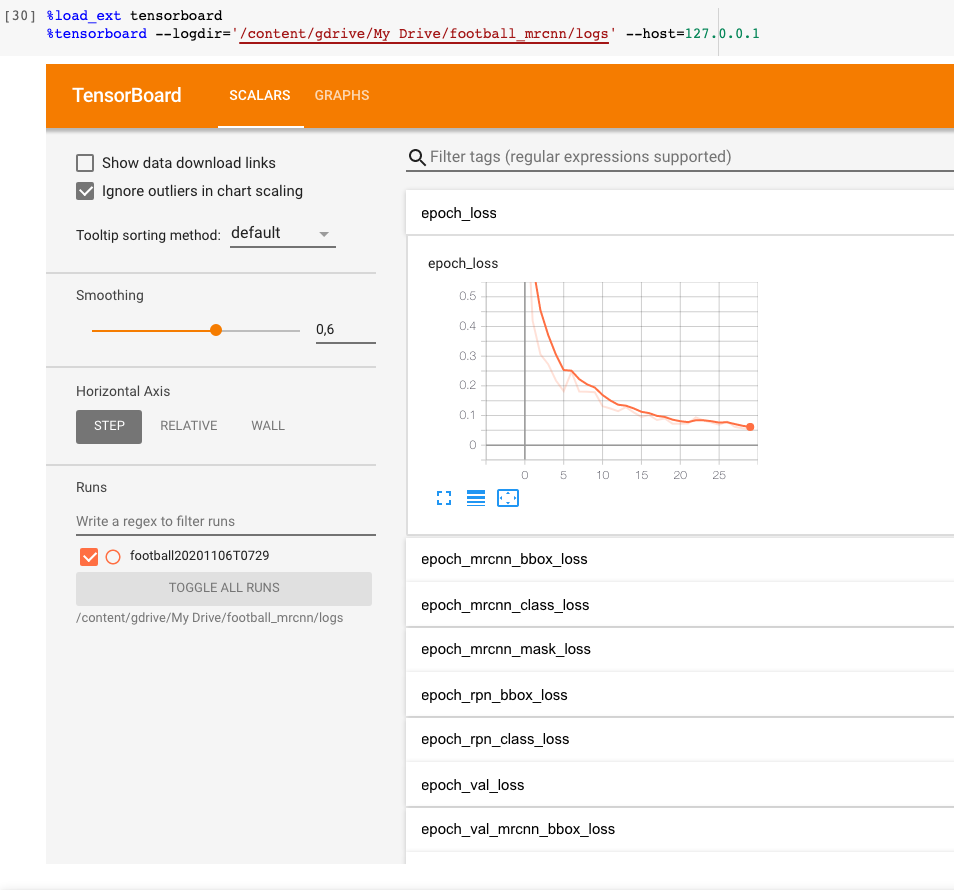
The training shows the different loss values at each epoch. Since Mask-RCNN involves RPN (Regional Proposal network) that predicts region proposals, along with class labels, bounding boxes, and mask predictions, we can see five different types of losses that have to be minimized. For more information about losses, see the Mask-RCNN architecture in this article or read the original paper here or see the script model.py.

I would suggest training on a GPU because Mask-RCNN is computationally heavy to train on a CPU. If you have a machine with GPU, you can just start training right away but if you don’t have it, you can use Google Colab as they provide free GPU access. Just mount your google drive into your Colab notebook using the code below. You will be asked to click on a link to authorize the mount. Copy the authorization code back into the notebook and you can obtain access to the data in your google drive in Google Colab.
from google.colab import drivedrive.mount('/content/gdrive')
The entire training for 30 epochs took about 30min for me (78 train + 21 validation images). If you are training on your own machine, the training can be visualized using this command in the terminal: tensorboard --logdir=/path_to_logs and then opening localhost:6006 in your browser. For training on Google Colab, you can visualize the losses through tensorboard using this command below.
%load_ext tensorboard%tensorboard --logdir=<path_to_logs> --host=127.0.0.1
For inference, you can load the model weights from one of the checkpoints saved in the logs folder and visualize the predictions for unseen instances. The first element ofresults on line 29 below gives a dictionary with keys about the following predictions:

The model does a pretty good job of identifying footballs in the images. It can also recognize masked footballs and difficult to isolate footballs like in the image below.

In this tutorial, you learned to collect and labeled data, set up your Mask RCNN project, and train a model to perform instance segmentation. The labeled data, the entire code, and the trained weights are available at my Github repo.
Hope you enjoyed the post! Leave your comments and suggestions below.
References
