Data Extraction
Context-aware data extraction from any doc, layout, language.
Scans, PDFs, e-invoices, unstructured files of Invoices, bank statements, AML packs, KYC documents, contracts; Staple extracts all of it and delivers structured, audit-ready output into the systems you already run.
Your documents have the data. Getting it out reliably is the problem.
Most extraction tools work on clean, standard documents. Complex tables, multilingual files, handwritten forms, dot-matrix scans: these are not edge cases. They are the daily reality for any enterprise operating across countries. The moment formats vary or languages switch, accuracy drops and your team fills the gap manually.
- Template-based OCR tools break when suppliers change their format or send documents in a different language. Every new document type is a new configuration job.
- Internal builds reach 70-80% accuracy on unstructured documents, then stall at POC because compliance will not sign off on output with no chain of custody.
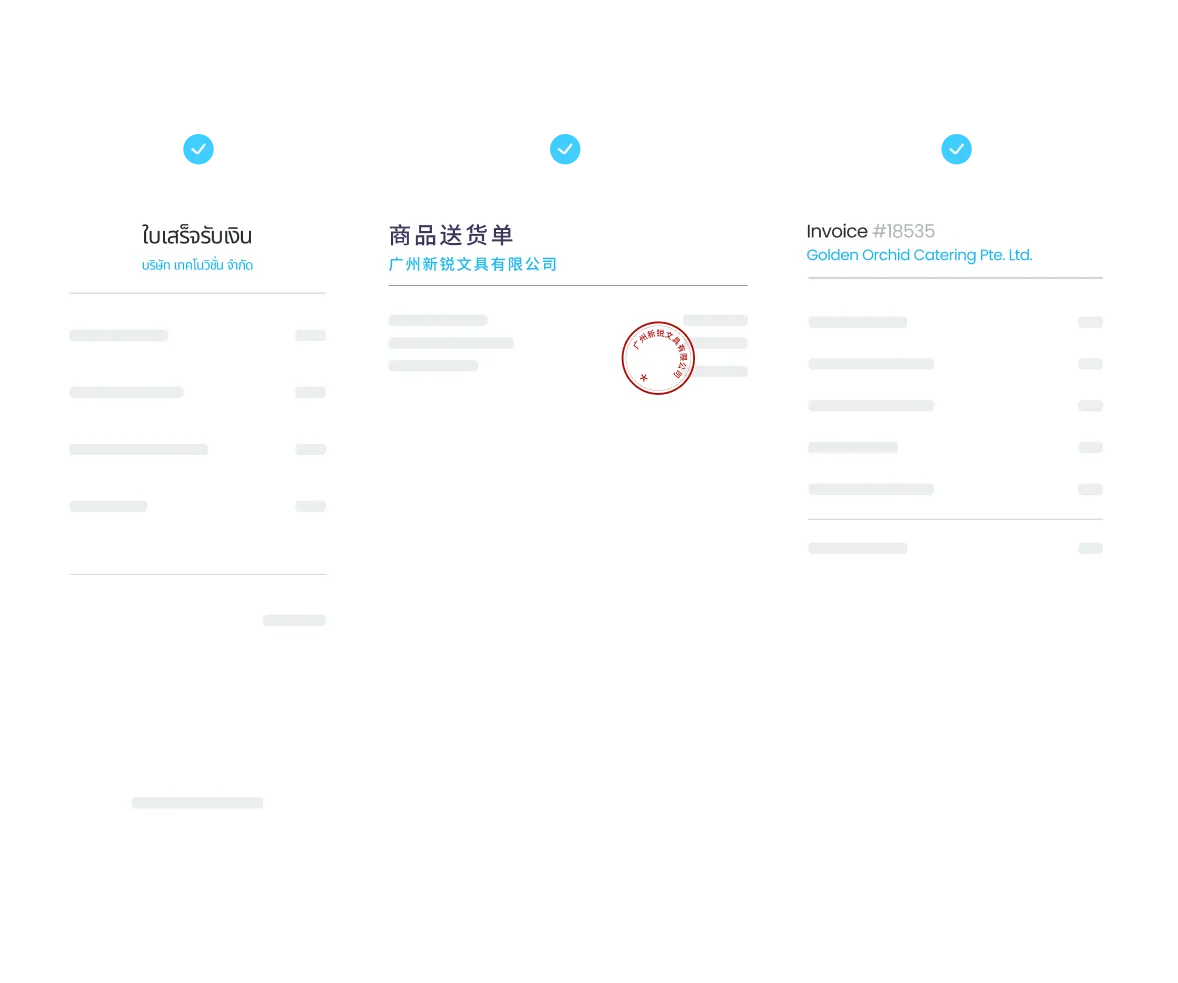
How Staple extracts data from your documents
Every document type, every format, every industry
Invoices, bank statements, KYC, contracts, e-invoices in XML, JSON, UBL, and PDF, scans, photos, dot-matrix prints: Staple processes all of them. No separate tool per document type, no separate process per format.
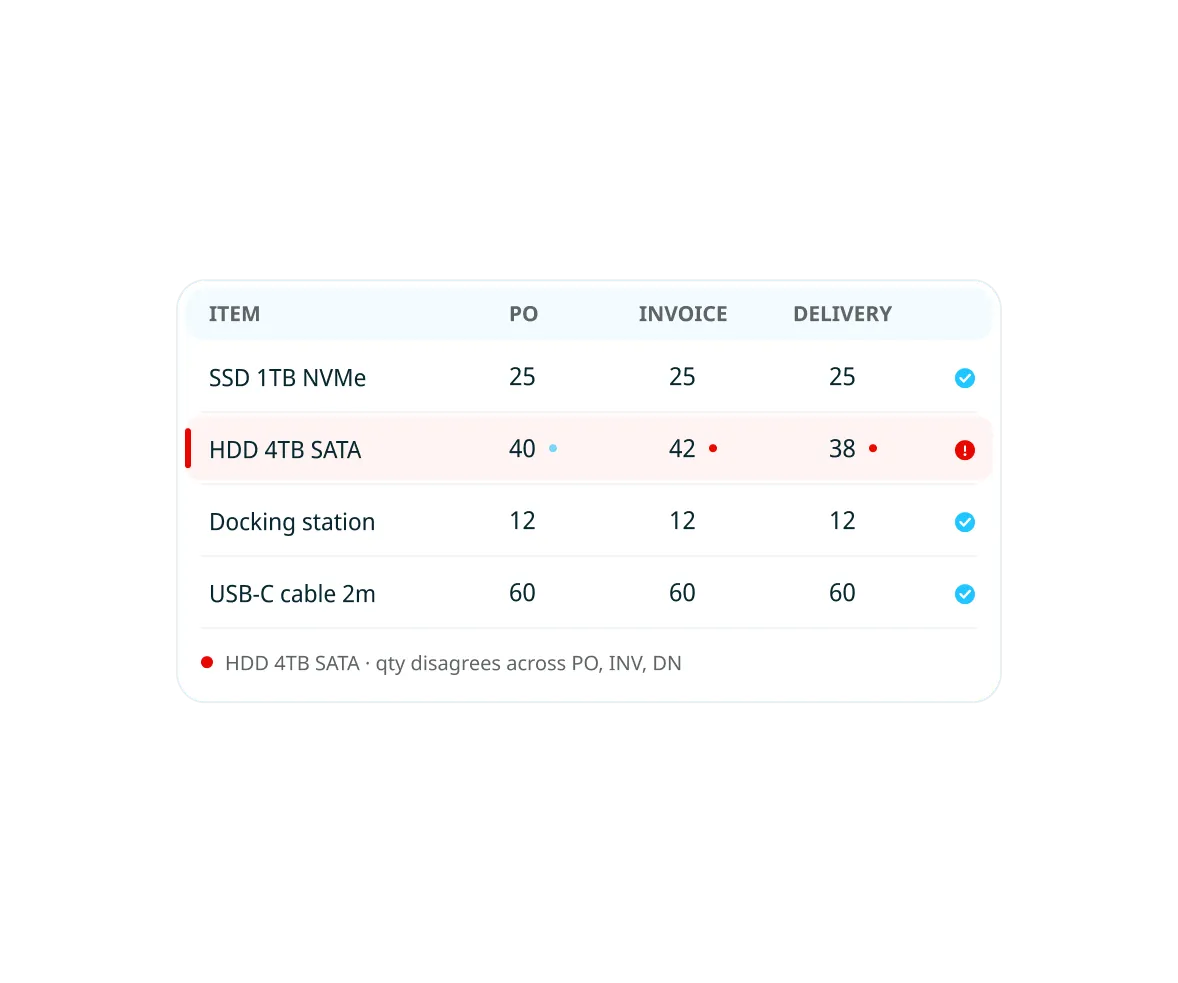
Reads what a field means, not where it sits
Context-based extraction, not template-based. Accuracy holds regardless of layout, language, or sender across 300+ languages. Handwriting, stamps, irregular formats, scanned documents: all handled in one pipeline without per-supplier configuration.
Every table, every line item, no exceptions
Dense line items, merged cells, nested hierarchies, multi-language tables: Staple extracts every row from any table structure without missing a field. Whether it is a 50-line purchase order, a financial statement with multiple table categories, or a delivery note in a vendor-native language, every line item comes out structured and complete.
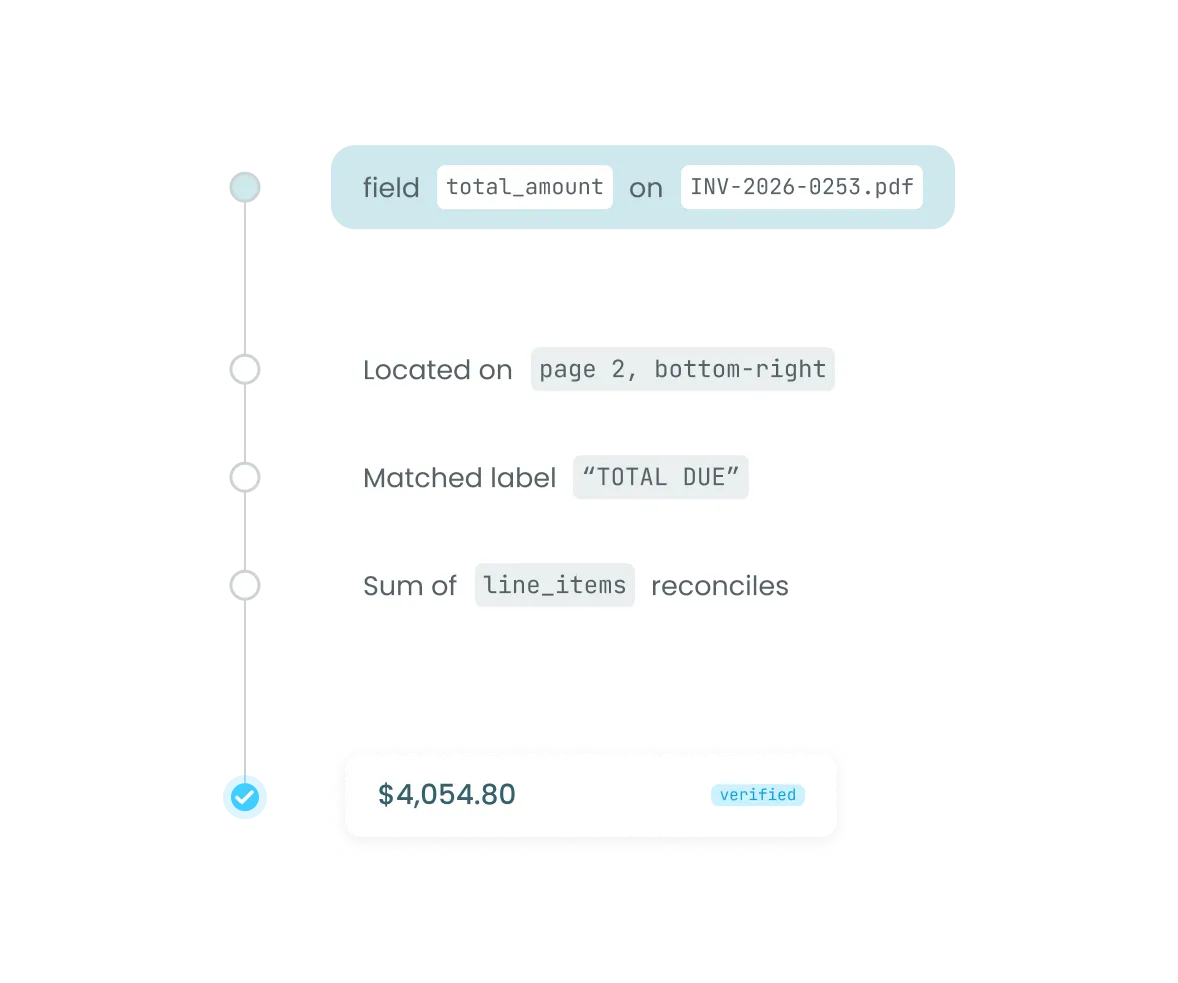
Verified. Sealed. Production-ready.
AI contextual verification checks every extracted field for meaning, not just value. Business rules flag anomalies against your thresholds and external validation with tax authorities (especially in e-invoicing). Every field that passes carries its source document, page reference, model version, and confidence score, cryptographically sealed, making it audit-ready.



Common questions
What is context-aware data extraction?
Context-aware data extraction is a method of extracting structured data from documents by understanding the meaning of each field in context, rather than relying on the position of data on the page. Template-based tools require a pre-configured layout for each document type. When layouts change, the template breaks. Context-aware extraction reads what a field means: a vendor name is a vendor name whether it appears at the top or middle of the document, whether the label says Supplier, Vendor, or From. Staple AI uses context-aware extraction across all document types, handling 300+ languages, irregular layouts, handwriting, and complex tables without per-document configuration.
How does context-aware extraction differ from template-based OCR?
Template-based OCR maps extraction rules to fixed positions on a document layout. It works when documents are standardised but fails when formats vary across senders, countries, or document types. Context-aware extraction reads the semantic meaning of each field regardless of where it appears on the page, so accuracy holds across variable layouts, languages, and document types. In a multi-document compliance review involving bank statements, proof of identity, source of wealth, and source of funds from different issuers and countries, context-aware extraction processes all of them in a single pipeline without per-issuer configuration. Staple AI's extraction is context-aware by design, with no templates to maintain and no manual reconfiguration when document formats change.
How does Staple AI handle multi-document packs like AML and KYC review files?
AML and KYC review packs typically contain multiple document types bundled together: bank statements, proof of identity, proof of address, source of wealth declarations, and source of funds evidence. Each document comes from a different issuer, in a different format, and carries different fields relevant to the compliance checklist. Staple AI splits and classifies each document in the pack automatically, extracts the relevant fields from each type, cross-references data across documents for consistency, and delivers a structured output mapped to the compliance checklist. A review that previously required three hours of manual data gathering is reduced to a structured, auditable output ready for the compliance reviewer to act on.
Why do internal LLM builds fail in regulated document data extraction?
Internal LLM experiments for document extraction typically reach 70 to 80 percent accuracy on well-structured documents but encounter three failure modes in regulated environments. First, accuracy degrades on edge cases: handwritten documents, multi-language packs, and irregular layouts outside the training distribution. Second, the output carries no chain of custody: there is no record of which model extracted which field, under which rules, and with what confidence, so compliance teams cannot sign off on it. Third, the build stalls at POC because regulated industries require explainability and reconstructability at the field level, not just an accuracy percentage. Staple AI was built for regulated environments with chain of custody, cryptographic sealing, and explainability built into every extraction result.
What is chain of custody in document data extraction?
Chain of custody in document data extraction is the ability to demonstrate, for every extracted field, exactly where it came from, how it was extracted, and who had access to it at each step. In a regulated industry, chain of custody is required to demonstrate that extracted data was not altered after extraction, that the extraction process is repeatable and consistent, and that the output is tied to a specific source document and page. Staple AI embeds chain of custody at the field level: every extracted value carries its source document reference, page number, extraction model version, confidence score, and a cryptographic seal that breaks if the value is changed after the fact.
How does Staple extract data from documents stored in legacy document management systems?
Legacy document management systems store documents but cannot perform intelligent extraction. They have no indexing across document types, no structured output capability, and no way to query data fields across files. Staple AI connects to these systems via API or file export, ingests the documents, and performs classification, extraction, and verification on each one. The structured output is delivered into the downstream system, whether that is an ERP, a compliance workflow platform, or a fund administration system. The legacy system continues to serve as the document repository. Staple AI adds the intelligence layer that was never built into it.
How does Staple handle complex tables, merged cells, and multi-language line items?
Complex tables are one of the most common failure points for template-based extraction tools. Merged cells, nested hierarchies, multi-column headers, and line items that span multiple rows break fixed-position extraction rules because the layout does not conform to a predictable structure. Staple AI extracts every row from any table structure by understanding the semantic relationship between headers and values, not by mapping to a fixed grid. A 50-line purchase order, a financial statement with multiple table categories, and a delivery note in a vendor-native language are all handled in the same pipeline. Every line item comes out structured and complete, regardless of how the table was formatted or which language it was written in.
How does Staple AI handle data extraction at scale without losing auditability?
Scaling document data extraction without losing auditability requires three capabilities working together: pre-processing that classifies each document type before extraction begins so mixed batches are handled correctly at volume; extraction that is consistent across document types, languages, and layouts so accuracy does not degrade as volume grows; and a tamper-evident audit trail that is generated automatically for every result so auditability is a property of the output rather than a manual process applied after the fact. Staple AI processes all three layers for every document at any volume, with chain of custody embedded in each result
What does audit-ready data extraction require in a regulated industry?
Audit-ready data extraction in a regulated industry requires more than high accuracy. It requires that every extracted field carry its full processing history: source document, page reference, extraction model version, confidence score, reviewer identity, and timestamp. It requires that this processing history be cryptographically sealed so any change after extraction is immediately visible. It requires that PII be automatically redacted before data is exported to downstream systems. And it requires that the output be explainable: when a regulator asks why a field carries a particular value, the system must be able to account for that decision without forensic reconstruction. Staple AI enforces all of these requirements at the field level across every document it processes.
See how Staple extracts data from your documents.
Book a 30-minute demo. Bring your own documents and we will run extractions on your actual files, across your layouts, in your languages.